这名字咋来得?
”endian“这个词出自Jonathan Swift在1726年写的讽刺小说《格列佛游记》(Gulliver's Travels)。小人国的内战就源于吃水煮鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开,由此曾发生6次叛乱,其中一个皇帝送了命,另一个丢了王位。
—— 《程序员的自我修养》A.1 字节序(Byte Order)
到底如何工作?
这里有个jargon叫做字节序(Byte Order),展开说就是 字节在通信过程中的传输顺序。这个术语中本身透露了一个信息,那就是以字节(byte,8bit)为单位进行传输的;另一个就是传输的顺序,顺序本身是无所谓的,只要大家在传输之前协定了就可以,你以怎样的顺序穿过来,我以逆过程来解开就可以了。但是问题就出在这里,比如一个整形数据:0x12345678,我可以这样传:0x12->0x34->0x56->0x78,也可以这样传:0x78->0x56->0x34->0x12,无所谓好坏,所以就有人按照前者那么传输数据,有人按照后者来传输数据。
数据传输发生在CPU->内存,也发生在PC->网络。以前者为例(后者是大端的传输方式,如果计算机采用小端存储,需采用函数转换下),假如CPU寄存器存的数是:0x12345678(先)和0x87654321(后),依次存到stack(栈向下生长,即由高地址->低地址生长)中,按照第一种方式将数据从CPU传输到内存中,则最后的内存分布如下:
[0x87654321]低地址
[0x12345678]高地址
这种是PowerPC系列处理器的方式,即大端(Big-Endian)
<程序员的自我修养如是说,木有mac机,无从考证。>
如果按照第二种方式传输到内存中,则最后的内存分布如下:
[0x21436587]低地址
[0x78563412]高地址
这种是x86的方式,即小端(Little-Endian),看看在vs调试时的内存分布。

以上这种表述是有jargon的,其中一个数据的最重要的位为MSB(Most Significant Byte/Bit),最不重要的位叫做LSB(Least Significant Byte/Bit),自然重不重要是看你在整个数据中所占的权重相关的,如0x12345678的MSB即为0x12(占大头,如果0x12没有了,那么整个数的值就下降了太多),LSB为0x78(最后两位,如果0x78没有了,对整个数的影响较小)。那么” Big-endian和Little-endian的区别就是big-endian规定MSB在存储时放在低地址,在传输时MSB放在流的开始;LSB存储时放在高地址,在传输时放在流的末尾。Little-endian则相反“。
那么到底是谁在决定是使用Big-endian,还是Little-endian?
在计算存储中是CPU,也就是CPU的体系结构,还是有点抽象啊。比如x86的是小端,power-pc的是大端。
那么ARM的呢(忘了补充,是 ARM Cortex-M3的,不晓得A系列和R系列的如何)?是可编程的,默认是小端的,不过还没有试过,有时间整下。下面是《ARM Cortex-M3》P115页的说明。
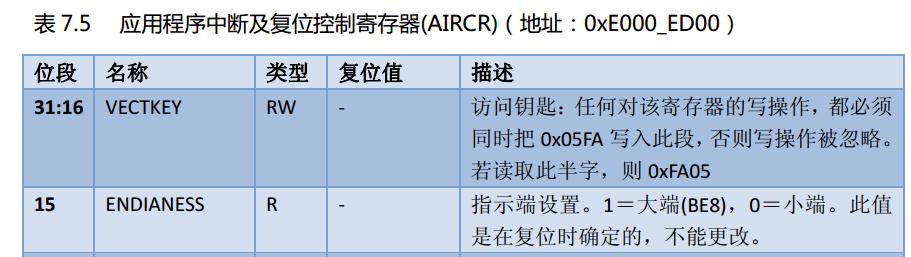
我觉得不管哪个体系结构,可能都是可编程的,只是如x86或者power-pc的寄存器没告诉你,说不定芯片制造商在调试芯片的时候还用过,不过如果一开用啥就应该是啥了,兼容么。
所以,大小端就目前看来,是人为规定的,没有统一的标准(当然也不是随意的,如TCP/IP的大端,我说的是统一的标准),比如ARM的,它干脆就设置成是可编程的,可以再启动的时候修改它的字节序模式,当然一旦启动时改定了,那之后就是不能变的,如果启动之后还可以改来改去,不可想象。不过一般也很少去改动,自己知道就好了,万一碰到发现得到的数据是有问题的,晓得从哪里入手就ok了吧。
检测方法呢?
最后附上三个监测大小端的方法:
C++ Code
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #include <stdio.h> #include <stdlib.h> #include <string.h> #include <assert.h> /* 宏+指针的形似区别大小端 */ const int endian = 0x12345678; #define is_big_endian3() (0x12 == *( char*)&endian) /* 利用指针来区分大小端 */ int is_big_endian1( void) { int i = 0x12345678; char *cPtr = ( char *)&i; return (0x12 == *cPtr); } /* 利用联合体来检测大小端 */ int is_big_endian2( void) { union t { int i; char c; } t1; t1.i = 0x12345678; return (0x12 == t1.c); } int main( void) { if(is_big_endian1()) { printf( "%s\n", "Big Endian"); } else { printf( "%s\n", "Little Endian"); } return 0; } |
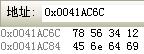
看它在内存中的存储顺序:
可以看到LSB(0x78)存在内存中的低地址,MSB(0x12)存在内存中的高地址。即x86的小端。
参考资料:
《ARM Cortex-M3权威指南》
《程序员的自我修养——连接,装载与库》